区块链学习4-以太坊基础知识
1. 基本知识
基本知识需要了解两部分
第一部分是以太坊版本演进过程:白皮书——>黄皮书——>Frontier版本——>Homestead版本——>Metropolis版本——>Serenity版本,目前处于Metropolis版本,也就是大都会,更多内容参考 以太坊发布过程。
另一部分是基本的概念,下面是以太坊中国社区有人整理的 Vitalik Buterin(以太坊创始人)在Ethereum Devcon3(以太坊第三次开发者大会)上的演讲《Ethereum in 25 minutes, vision 2017》,基本上对以太坊做了一个全面的描述。
Vitalik: 25分钟认识以太坊(上),Vitalik: 25分钟认识以太坊(下)
2. 工具
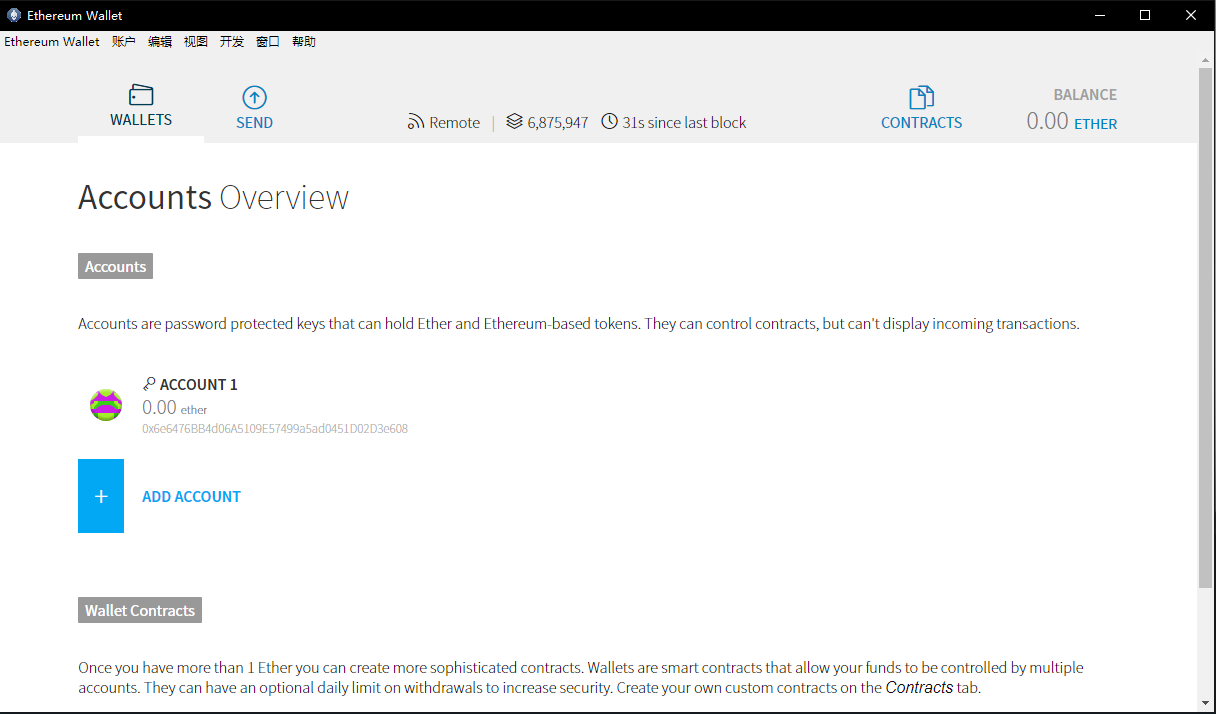
以太坊钱包 mist 是以太坊基金会主推的项目,目前处于测试阶段,开源,所有人都可以贡献代码。可以离线管理账户,包括账户的创建、备份、导入、更新等,现在最重要的功能是进行以太币的交易,但其实它定位不只是一个钱包,而是将来Dapp的市场,类似于安卓的应用商店,在这里可以有你的账号,可以浏览、发布和买卖以太坊的Dapp应用。目前因为开发还不够全面,名称暂时显示为 Ethereum-Wallet。
下载地址(需要科学上网):Releases
刚打开的时候mist会同步全网信息,需要的时间可能久一点,同步完成后可以进行创建账户、设置密码和转账等操作。其界面如下:
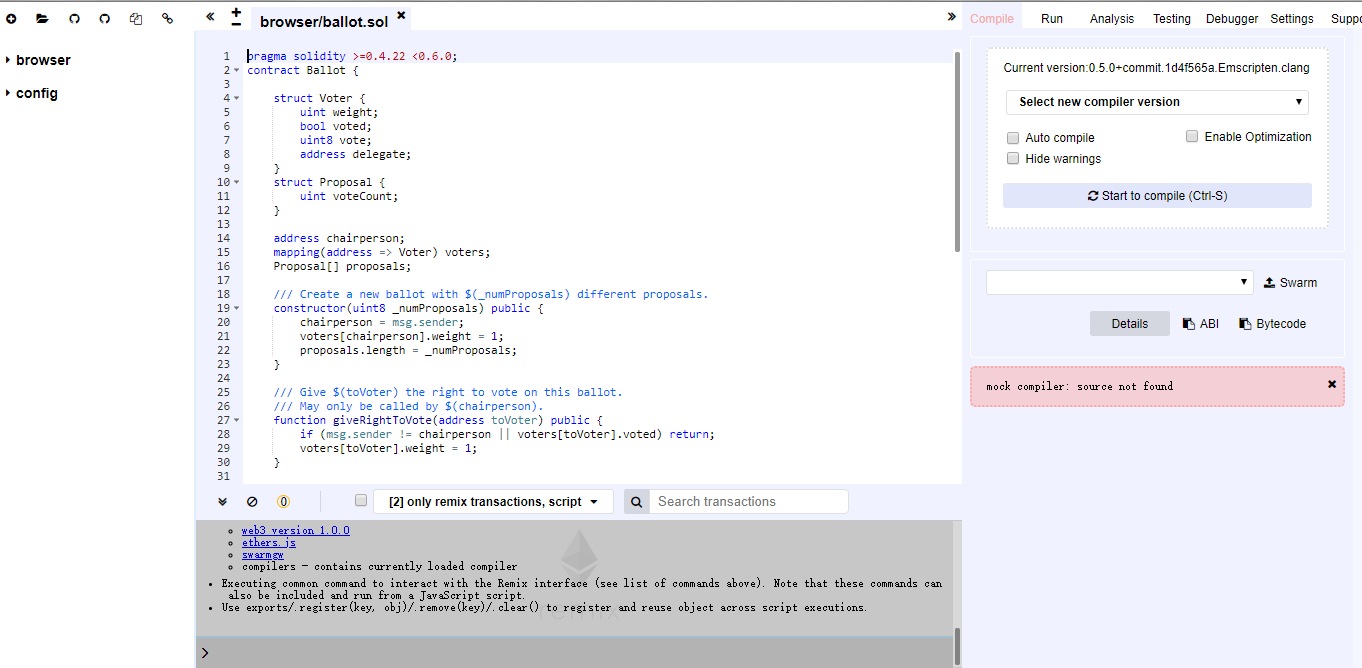
Remix 是一个基于浏览器的编译器和IDE,是用C++开发的,客户端不需要安装,能够使用Solidity语言构建以太坊合约并调试。界面如下:
以太坊客户端以编写语言分类,在github上分成了不同项目,下面进行介绍。目前最流行的应该是 Go 语言客户端 geth,star和fork的数量都远远超过其它客户端,项目介绍是「以太坊协议的官方 go 语言实现」,可以实现搭建私有链、挖矿、账户管理、部署智能合约、调用以太坊接口等常用功能。。
3. 架构
以太坊整体架构如图

各层介绍如下
- 底层服务:底层服务包括P2P网络、LevelDB数据库、密码学算法和分片(Sharding)优化。LevelDB数据库是谷歌开发的一个轻量,高效的key-value数据库,在以太坊中用来存储区块、交易等数据。而分片则是为了解决以太坊,甚至所有公有区块链目前面临的低吞吐量和高延迟问题,因为问题的核心在网络中的节点需要处理所有的交易,分片就是将网络中的工作分摊给所有参与的节点。分片优化使得可以并行验证交易,加快了交易验证速度,从而加快了区块生成速度。
- 核心层:包括区块链、共识算法和以太坊虚拟机。区块链和共识算法是区块链平台的基础,以太坊虚拟机则是以太坊的主要特点,用来作为运行智能合约的载体。
- 顶层应用:包括API接口、智能合约和去中心化应用。以太坊的Dapp通过Web3.js与智能合约层进行信息交换,所有的智能合约都运行在EVM上,并会用到RPC的调用。
4. 区块
以太坊使用了比特币区块链的技术,但做了一些调整,区块由 区块头、交易列表 和 叔区块头 三部分组成。
4.1 区块头
区块头包含下列信息:
- 父块的散列值(Prev Hash)
- 叔区块的散列值(Uncles Hash)
- 状态树根散列值(stateRoot)
- 交易树根散列值(Transaction Root)
- 收据树根散列值(Receipt Root)
- 时间戳(Timestamp)
- 随机数(Nonce)
以太坊的一个创新是保存了三棵Merkle树根,分别是状态树、交易树和收据树。存储三棵树可方便账户做更多查询。
4.2 交易列表
和比特币区块链相同
4.3 叔区块头
叔区块是父区块的父区块的子区块,但不是自个的父区块,或更一般的说是祖先的子区块,但不是自己的祖先。当矿工打包的时候发现有这样的块存在,就把它打包进去,称为叔块。如图,黄色的101是一个叔块
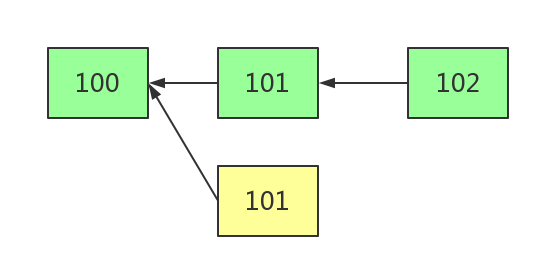
叔块概念与出块时间有关。比特币平均出块时间间隔为10分钟,出现叔块的情况概率比较小,当时中本聪设定的这种情况的叔块是做无用功,不会有任何奖励。但是以太坊为了缩短出块时间到10s出头,那么叔块产生的概率就比较高了,如果类似比特币的设计,会有很多矿工因为生产了叔块而获取不到任何奖励,矿工的积极性会降低,不利于以太坊生态发展,所以V神引入了叔块的概念,这种情况下矿工打包叔块进区块,叔块生产者和打包叔块的矿工都会有一定的奖励。
一篇介绍见Toward a 12-second Block Time
5. 账户
以太坊中有两种类型的账户
- 外部账户(Externally Owned Accounts)
- 合约账户(Contracts Accounts)
外部账户是由外部角色拥有的账户,一个外部账户:
- 有一个以太币余额
- 可以发送交易(以太币的转移或触发合约代码)
- 由一个私钥所控制
- 没有关联代码
合约账户,顾名思义,是合约的账户,它
- 有一个以太币余额
- 有关联代码
- 由交易或从其他合约收到的消息所触发执行
- 代码执行
- 可以处理任意复杂度的操作(图灵完备)
- 可以操作它自己的持久化存储,比如可以有它自己的永久状态
- 可以调用其他合约
以太坊区块链上的所有动作,都被设定为由外部账户所发出的交易所触发。每当合约账户接收到交易,它的代码会根据作为交易的一部分传入的参数来具体执行。将在网络中每个节点上的以太坊虚拟机中被执行,并被作为它们对新区块的验证结果的一部分。
账户的地址由公钥得到,而公钥由私钥得到,所以私钥文件是最重要的,也是需要保存的唯一文件。目前常见的私钥有三种形态:Private key、Keystore&Password 以及 Memonic code。
- Private key就是一份随机生成的256位二进制数字,用户甚至可以用纸笔来随机地生成一个私钥,即随机写下一串256位的仅包含“0”或“1”的字符串。该256位二进制数字就是私钥最初始的状态。
- 而在以太坊官方钱包[插图]中,私钥和公钥将会以加密的方式保存一份JSON文件,存储在keystore子目录下。这份JSON文件就是Keystore,所以用户需要同时备份Keystore和对应的Password(创建钱包时设置的密码)。
- 最后一种Memonic code是由BIP 39方案提出的,目的是随机生成12~24个比较容易记住的单词,该单词序列通过PBKDF2与HMAC-SHA512函数创建出随机种子,该种子通过BIP-0032提案的方式生成确定性钱包。
6. 共识机制
以太坊中专门设计的PoW算法称为Ethash。
但以太坊的目标是转换到PoS。PoS即基于网络参与者目前持有的数字货币的数量和时间进行利益分配。在以太坊中,PoS算法可以这样描述:以太坊区块链由一组验证者决定,任何持有以太币的用户都能发起一笔特殊形式的交易,将他们的以太币锁定在一个存储中,从而使自己成为验证者,然后通过一个当前的验证者都能参与的共识算法,完成新区块的产生和验证过程。
有许多共识算法和方式对验证者进行奖励,以此来激励以太坊用户支持PoS。从算法的角度来说,主要有两种类型:基于链的PoS和BFT(Byzantine Fault Tolerant,拜占庭容错)风格的PoS。
在基于链的PoS中,该算法在每个时隙内伪随机地从验证者集合中选择一个验证者(比如,设置每10s一个周期,每个周期都是一个时隙),给予验证者创建新区块的权利,但是验证者要确保该块指向最多的块(指向的上一个块通常是最长链的最后一个块)。因此,随着时间的推移,大多数的块都收敛到一条链上。
在BFT风格的PoS中,分配给验证者相对的权利,让他们有权提出块并且给被提出的块投票,从而决定哪个块是新块,并在每一轮选出一个新块加入区块链。在每一轮中,每一个验证者都为某一特定的块进行“投票”,最后所有在线和诚实的验证者都将“商量”被给定的块是否可以添加到区块链中,并且意见不能改变。
许多早先的PoS算法中,生产区块只会产生奖励而不会惩罚。但这样会出现无利害关系问题。该问题有两种解决方案。见 共识算法的比较:Casper vs Tendermint
同时,其中的Casper正是现在以太坊的共识算法,这是以太坊转向PoS的过渡。
7. Merkle Patricia Tree
简称MPT,是Merkle Tree和Patricia Tree的结合,下面的介绍转自CSDN。
Merkle Tree
区块链 P2P 网络中,如果需要传输的数据很大,就需要同时从多个机器上下载数据,而且很可能有些机器是不稳定 (可能下载速度很慢) 或者不可信的(需要重新下载)。为了大块数据并验证,更好的办法是把大文件分割成小的数据块(例如把大文件分割成 4K 为单位的小数据块)。这样的好处是如果小块数据在传输过程中损坏了或者是错误的数据,那么只要重新下载这一块数据就行了,不用重新下载整个文件。
由于只有大文件内容的 hash, 当其中一块小数据错误时,我们是能检出由小块数据拼凑出来的大数据是错误的,但是我们不知道哪块小数据是错误的,就没法通过重传错误的小数据来纠正。哪怎么处理呢?为每个小块生成 hash, 节点先把小块数据的 hash 都下载下来,然后就可以验证一个一个验证小块数据是否正确了。那问题又来了,小块数据的 hash 的正确性谁来保证呢?信任节点,比如 BT 论坛上的 bt 种子文件,这个种子文件就记录了原始文件的小块数据的 hash. 验证问题解决了,但是多出来了小块数据 hash,当块数据很大时,这个数据量也不小。因而 Merkle Tree 出来了,它就是用来解决这个问题的。
小块数据的 hash 两两组合再次生成新的 hash, 然后新生成的 hash 又两两合并生成更新的 hash, 直至最后两个 hash 生成一个 hash root, 这个叫 merkle root(默克尔根)。可见 merkle tree 和传统 bt 分片技术只是对小块数据 hash 的组织方式不一样。
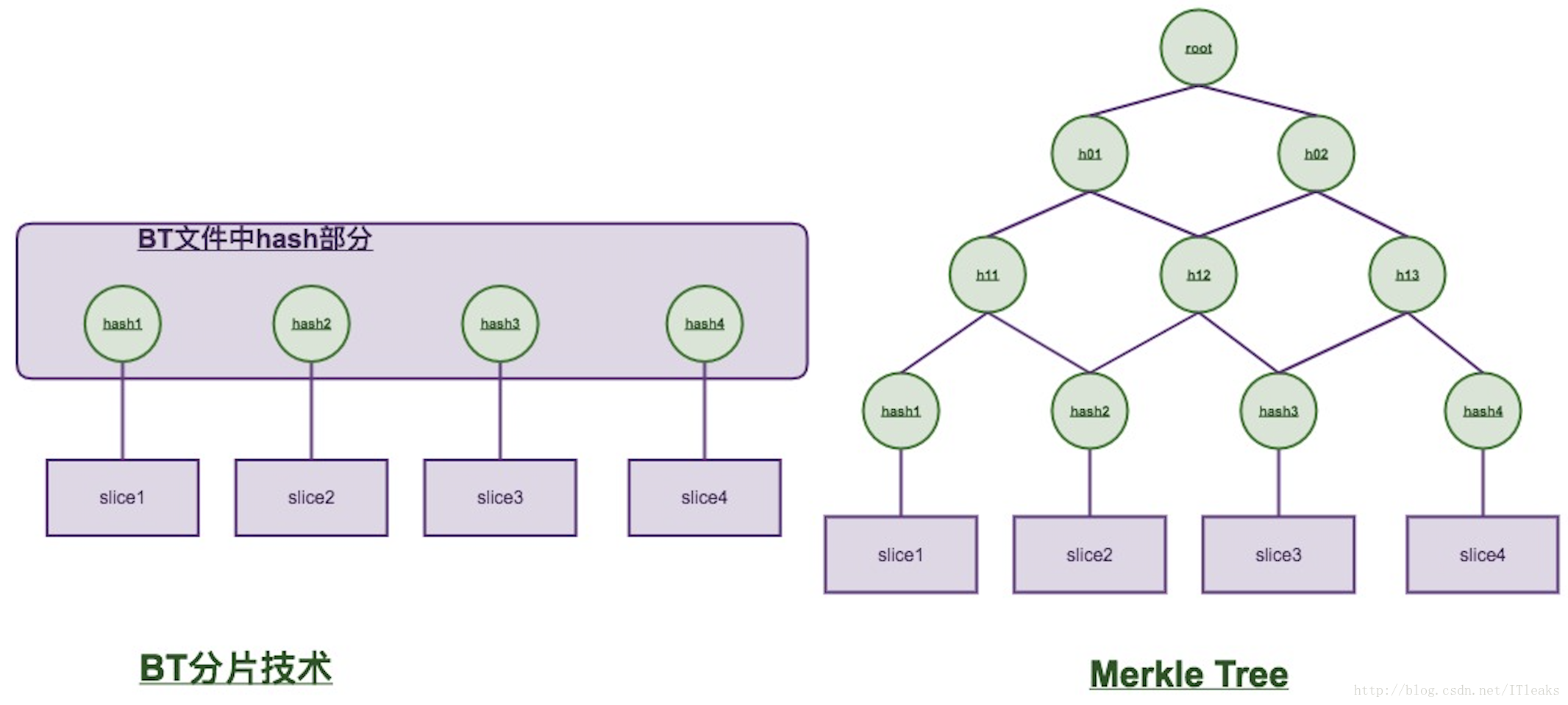
看到上面的图,你可能会说,merkle tree 不是生成更多 hash 数据了啊,怎么能降低数据传输量。确实,对于数据发送方来说,相比传统分片技术,它是需要保存完整 merkle tree, 会多占用一点空间。但是对于接受方来说,它在验证某一块数据不需要下载全部 hash, 只需一段 merkle 路径即可,比如下图

如果要验证 slice2 数据的正确性,只需要拿到 hash1, h12, h02 这 3 个 hash 再加上本地存储的 root hash, 就可以验证了。需要传输的 hash 数据量从 n 变为 log2n.
总结,Merkle root(包含在区块头里) 是从可信渠道下载的 (主链或者可信节点),接收到数据及这个数据对应的 Merkle 验证路径即可验证该数据的正确性。
Patricia Tree
patricia tree 前缀树,是一种编码方式, 它是传统 trie 的改进。
Trie 树
Trie,又称前缀树或字典树,是一种有序树状的数据结构,其中的键通常是字符串,常用语存储 Key-value 数据结构。
Trie 与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,节点对应的 key 是根节点到该节点路径上的所有节点 key 值前后拼接而成,节点的 value 值就是该 key 对应的值。根节点对应空字符串 key。
如果 key 是英文单词,trie 的每个节点就是一个长度为 27 的指针数组,index0-25 代表 a-z 字符,26 为标志域。

上面的存储的数据如下:
[‘a’] = V1, [‘ab’] = V3, [‘b’] = V2, [‘ba’] = V4, [‘baa’] = V5, [‘zaab] = V6
从上面可以看出 zaab 这个 key, 没有和任何其他 key 共享字段,但是却产生了 6 层,这种无用的深度增加有什么方法减呢?Patricia Tree 就可以解决这个问题
Merkle Patricia Tree 对 trie 的改进
上面 tries 出现的问题的根本原因是每个前置节点只能表示一个字母,key 有多长,树的深度就会多长,不管这个 key 有没有和其他 key 共享部分 key。因而允许一个节点表示变长的 key 就可以解决这个深度,具体以官方的下图为例:

上图存储的 key-value 如下:
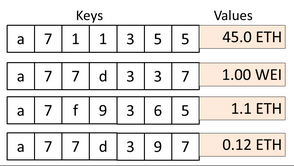
从前面结构图可以看出,Merkle Patricia Tree 有 4 种类型的节点:
叶子节点(leaf),表示为 [key,value] 的一个键值对。和前面的英文字母 key 不一样,这里的 key 都是 16 编码出来的字符串,每个字符只有 0-f 16 种,value 是 RLP 编码的数据
扩展节点(extension),也是 [key,value] 的一个键值对,但是这里的 value 是其他节点的 hash 值,通过 hash 链接到其他节点
分支节点(branch),因为 MPT 树中的 key 被编码成一种特殊的 16 进制的表示,再加上最后的 value,所以分支节点是一个长度为 17 的 list,前 16 个元素对应着 key 中的 16 个可能的十六进制字符,如果有一个 [key,value] 对在这个分支节点终止,最后一个元素代表一个值,即分支节点既可以搜索路径的终止也可以是路径的中间节点。分支节点的父亲必然是 extension node
空节点,代码中用 null 表示
原理解释
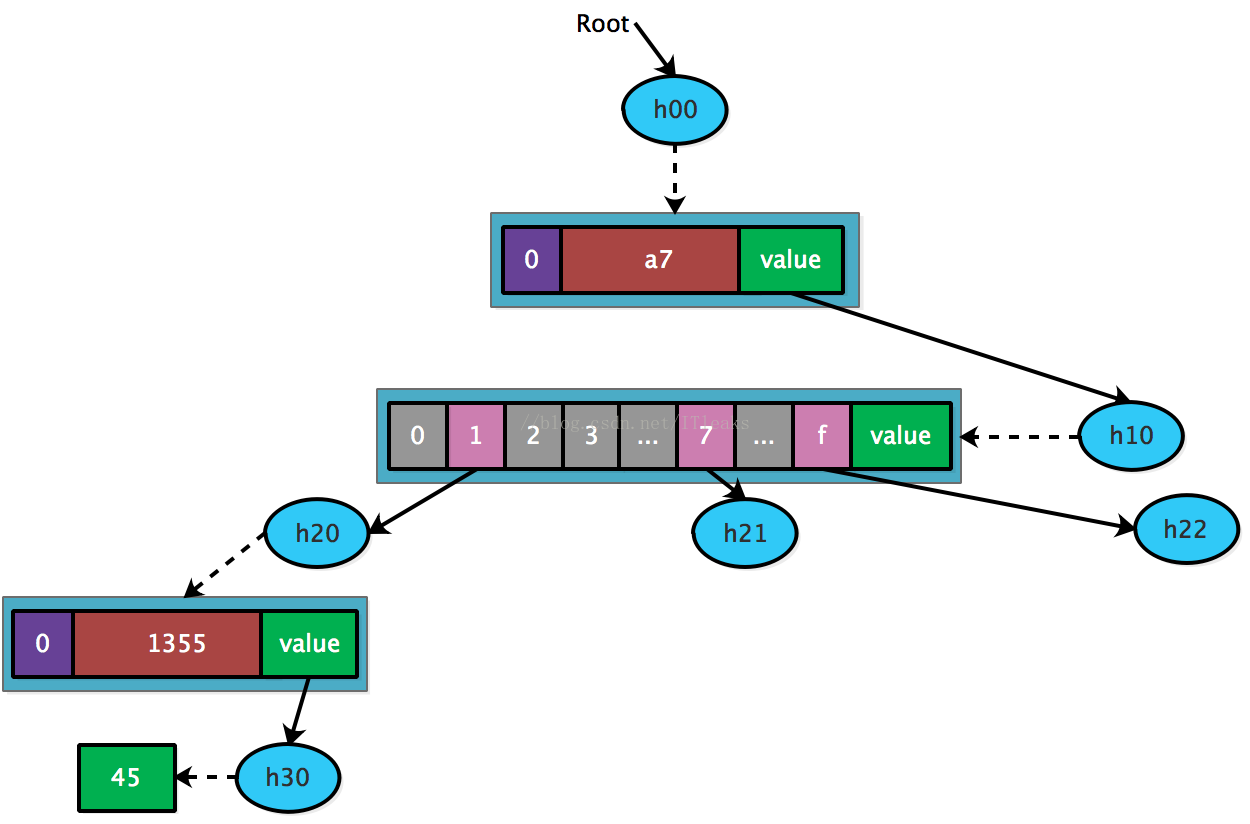
插入第一个 <a711355, 45>,由于只有一个 key, 直接用 leaf node 既可表示

接着插入 a77d337, 由于和 a711355 共享前缀’a7’, 因而可以创建’a7’扩展节点。
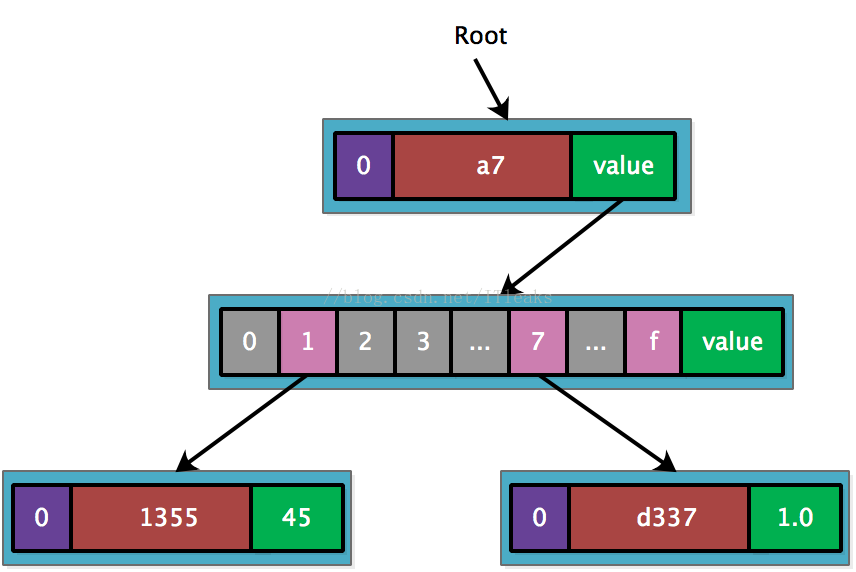
接着插入 a7f9365, 也是共享’a7’, 只需新增一个 leaf node.
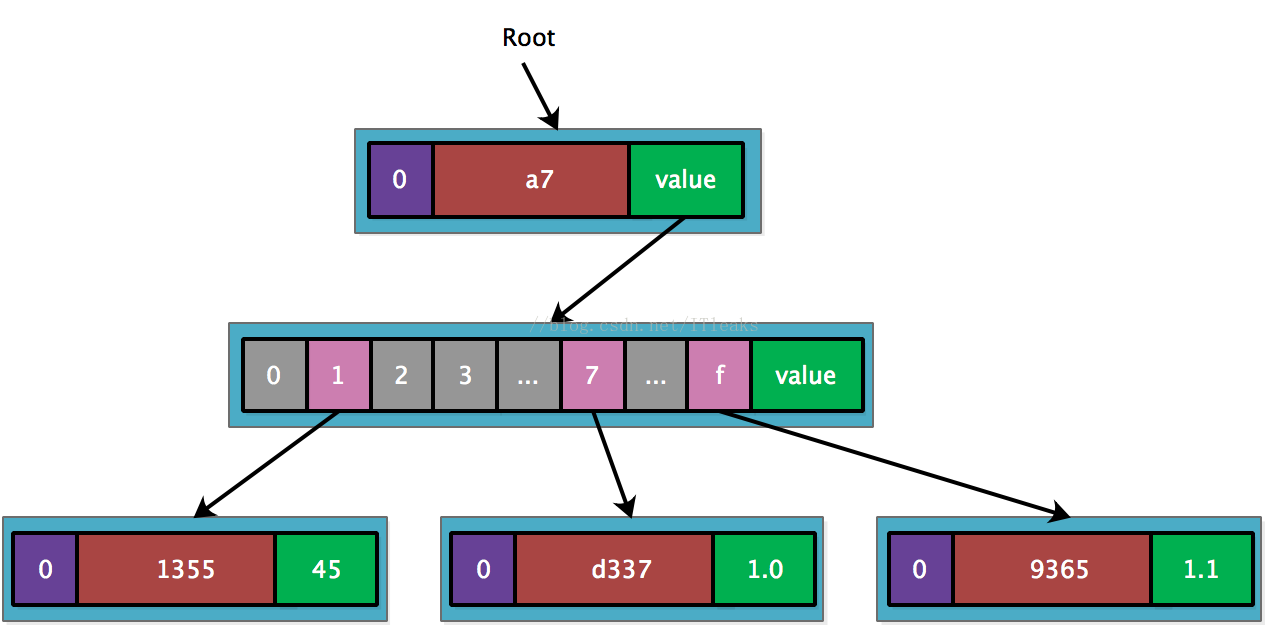
最后插入 a77d397, 这个 key 和 a77d337 共享’a7’+’d3’, 因而再需要创建一个’d3’扩展节点

MPT 中的 Merkle Tree 哪去了
前面为了和官方图一致,将叶子节点和最后的 short node 合并到一个节点了,事实上源码实现需要再深一层,最后一层的叶子节点只有数据
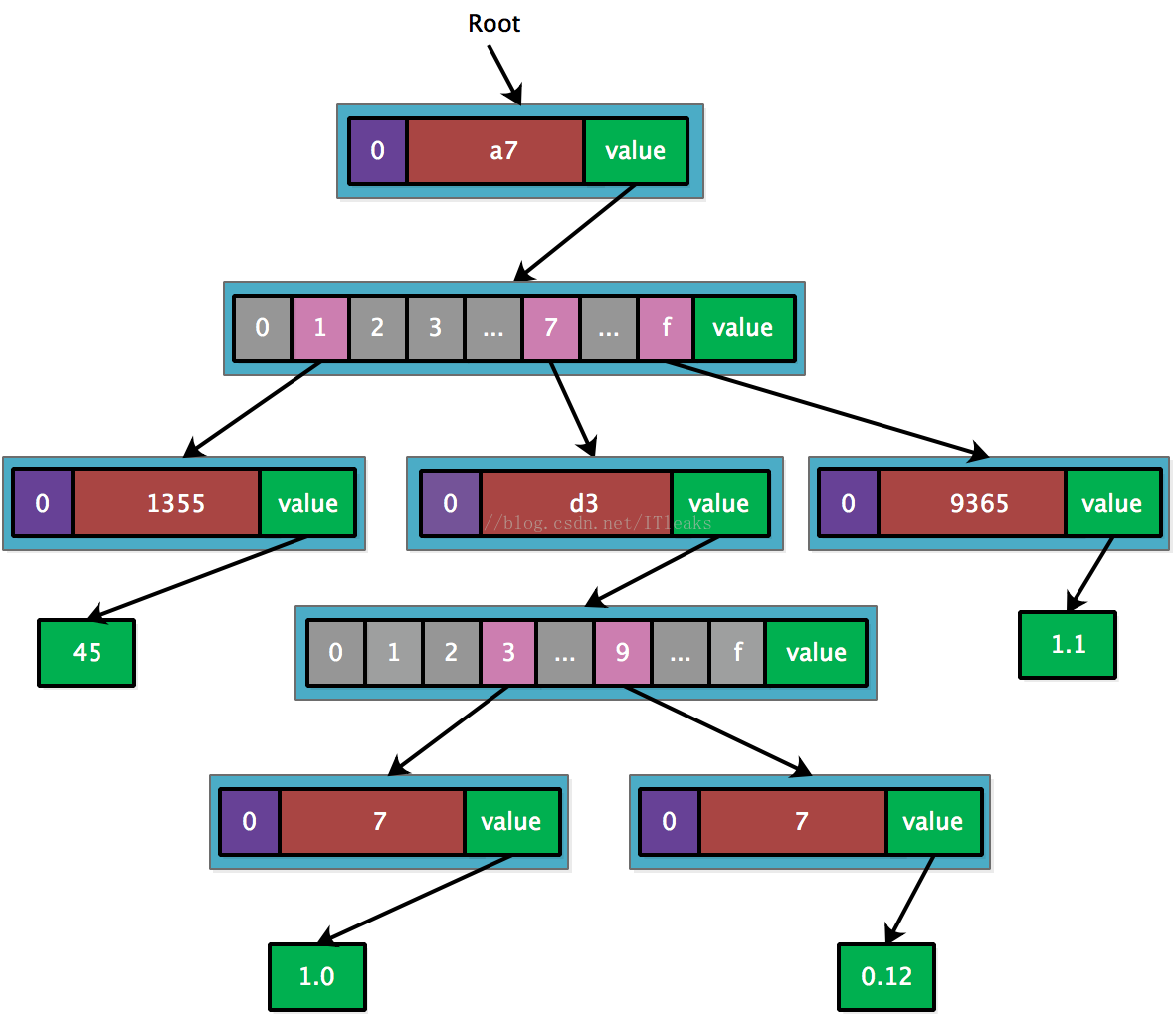
MPT 节点有个 flag 字段, flag.hash 会保存该节点采用 merkle tree 类似算法生成的 hash, 同时会将 hash 和源数据以 <hash, node.rlprawdata> 方式保存在 leveldb 数据库中。这样后面通过 hash 就可以反推出节点数据。具体结构如下 (蓝色的 hash 部分就是 flag.hash 字段)
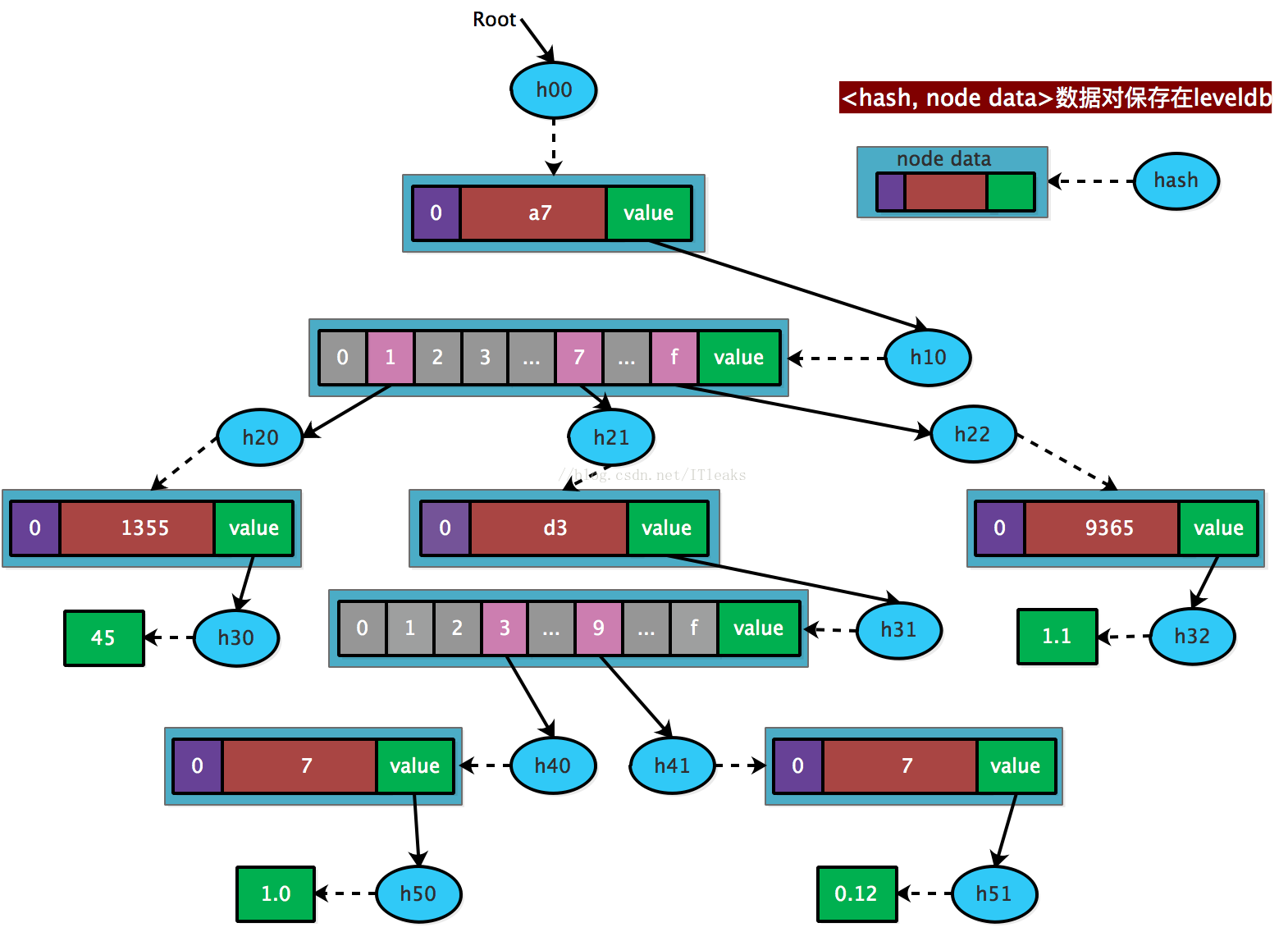
这样一个结构的核心思想是:hash 可以还原出节点上的数据,这样只需要保存一个 root(hash),即可还原出完整的树结构,同时还可以按需展开节点数据,比如如果只需要访问 < a771355, 45 > 这个数据,只需展开 h00, h10, h20, h30 这四个 hash 对应的节点
8. ENS
ENS(Ethereum Name Service,以太坊域名服务)是建立在以太坊区块链上的分布式、开放的命名系统。在以太坊网络中,地址通常是一连串长而复杂的散列地址,比如用户的地址和智能合约的地址。在这种情况下,用户记住一个地址是十分困难的。为了方便用户,以太坊推出了可以将散列地址“翻译”成一个简短易记的地址的ENS命名服务。用户要是想执行合约或者账户转账,只要向ENS提供的“翻译”地址发起交易就可以了,不用再输入一连串的散列地址。从这方面来看,ENS很像我们平时所熟知的DNS服务。比如,A要给B转一笔钱,当A发起交易时,在收款人地址处不用再填写B的散列地址,填写B的简单易记的钱包域名(B.myetherwallet.eth)也能正常交易。
ENS构成
ENS由三个主要构件组成,它们分别是注册表(registry)、解析器(resolver)和注册服务(registrar)。其中注册表是系统的核心不可变的部分,解析器最终由用户实现,注册服务是在ENS中拥有名称并根据规则分配子域的智能合约。ENS是以太坊基金会提供的去中心化应用,总的来说,ENS做了两件事:使用户注册支持智能合约运行的域名和利用底层设备标识符解析部分域名。
域名获取
用户要想获得域名的所有权,主要通过竞拍的方式。ENS拍卖采用的是维克里拍卖(集邮者拍卖)方式,该方式也被称为第二密封拍卖,即所有买家通过密封投标的方式竞价,出价最高的投标者将获得被拍卖的商品,但支付第二高的出价即可。
用户注册一个域名需要完成以下过程。 1)用户通过交易执行智能合约,向合约提供自己想要注册的域名。 2)如果该域名已被注册,那么用户要么重新提交新域名,要么与已经注册该域名的人交易以获得该域名;如果该域名正在被竞拍,那么用户将参加竞标,向合约投入认为比其他竞标者更高的竞价金,然后等待竞价期结束;如果该域名没有被注册或竞拍,那么需要用户发起竞拍,向合约投入竞价金,等待竞价期结束。 3)竞拍过程中用户只有一次出价机会,且其竞价对其他用户来说是不可知的,用户并不知道与他竞争的用户的出价,所有人都支付自己愿意付出的最高价格作为竞价,因此即使用户出价很低,但是只要没人与他竞争,或者竞标价格都比他低,那么该用户也能得到域名的所有权。竞价保密是为了防止投机者在竞价即将结束时投入最高价,影响竞价的公平性。 4)竞价截止后进入揭标环节(向其他用户显示竞价),所有参加竞标的用户必须揭标,否则其竞价金的99.5%会进入黑洞(被销毁且无法找回)。 5)揭标之后,出价最高的用户获得竞标胜利,并将以第二竞价的金额获得该域名,多余金额将会退回到该账户的钱包。如果有多名用户投标的价格完全相同,那么最早投标的人将获胜。竞价失败用户的竞价金的99.5%也会返还到各自账户。 6)在域名持有期内,用户可以将域名绑定到自己的以太坊地址、转移域名的使用权、添加设置子域名等,甚至还可以转让域名的所有权。
其它考虑
注意,ENS注册系统并不会产生收益,所有资金都作为保证金或者被销毁。被销毁的资金将被转移到地址0xdead,意味着不可找回。购买域名的竞价金以保证金的形式存放在一个独立的个人契约账户中,一年后用户可以放弃该域名的所有权,那么他可以拿回这笔保证金。肯定有读者想:既然能够返回押金,那么就用ENS智能合约规定的最低价格0.01ETH竞标到尽可能多的ENS,放在手中,万一以后转让给他人说不定还能大赚一笔!这种情况是不会发生的,首先,对于一些热门的ENS,较低的ETH肯定无法成功竞标,而且ENS竞标是一个运行智能合约的过程,既然是运行智能合约,那么肯定要花费一定的ETH费用,而且即使花费了大笔的交易费用得到大量的ENS,这些ENS也大多是无人问津的,对于那种想要“广撒网”的投机者来说,这无疑是一笔“亏本买卖”。总之,以太坊提倡的是“用你觉得合理的价位竞标你真正需要的ENS”。
 支付宝
支付宝 微信
微信