警告
本文最后更新于 2020-07-25,文中内容可能已过时。
本文关心 map 的底层实现、map 的扩容机制和 map 遍历的随机性。
先解答问题
- map 是实现是哈希表+链地址法解决冲突;
- map 扩容每次增加一倍的空间;
- map 遍历具有随机性,不要主观地认为遍历的顺序就是插入的顺序。
实际上,除了基本的结构定义,map 的初始化、访问、删除、扩容、遍历等操作并没有完全理解,留待之后再说,先占坑。
1. 实现
Go 中映射(map)的底层实现是哈希表,位于 src/runtime/map.go 中,数据被放到一个 buckets 数组里,每个 bucket 包含最多 8 个键值对。key 的哈希值低 8 位用于选择 bucket,高 8 位用于区分 bucket 中存放的多个键值。如果超过 8 个键被放到同一个 bucket,使用一个额外的 bucket 来存储。
核心的结构体主要是 hmap 和 bmap,前者就是这个 bucket 数组,后者就是单个 bucket 的结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| // map的基础数据结构
type hmap struct {
count int // map存储的元素对计数,len()函数返回此值,所以map的len()时间复杂度是O(1)
flags uint8
B uint8 // buckets数组的长度,也就是桶的数量为2^B个
noverflow uint16 // 溢出的桶的数量的近似值
hash0 uint32 // hash种子
buckets unsafe.Pointer // 指向2^B个桶组成的数组的指针,数据存在这里
oldbuckets unsafe.Pointer // 指向扩容前的旧buckets数组,只在map增长时有效
nevacuate uintptr // 计数器,标示扩容后搬迁的进度
extra *mapextra // 保存溢出桶的指针数组和未使用的溢出桶数组的首地址
}
type mapextra struct {
overflow *[]*bmap // overflow contains overflow buckets for hmap.buckets.
oldoverflow *[]*bmap // oldoverflow contains overflow buckets for hmap.oldbuckets.
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
// 桶的实现结构, hmap的buckets指针指向该结构
type bmap struct {
// tophash存储桶内每个key的hash值的高字节
// tophash[0] < minTopHash表示桶的疏散状态
// 当前版本bucketCnt的值是8,一个桶最多存储8个key-value对
tophash [bucketCnt]uint8
// 下面紧跟存放的键值对,存放的格式是所有的 key,然后是所有的 value,
// 之所以不是一个 key 跟随一个 value,是为了消除填充所需要的间隙,因为
// key 与 value 的类型不一致,占用的内存大小不一致
// 最后是一个溢出指针
}
|
hmap 是哈希表的基础结构,hmap.buckets 实际指向 buckets 数组,hmap.oldbuckets 和 hmap.nevacuate 用于扩容,之后介绍,hmap.extra 保存溢出桶的地址的数组以及未使用的溢出桶数组的首地址。
bmap 是单个桶的结构,是一个长度为 8 的数组,数组每个元素的值是 key 的哈希值的高 8 位,数组之后是 8 个 key,然后 8 个 value,最后一个溢出指针,溢出指针指向额外的桶链表,用于存储溢出的数据。用图描述如下

2. 访问
主要是 map.go 文件中的几个 mapaccess 函数,基本逻辑为

找不到 key,就返回该类型的零值。
3. 分配
分配的意思是向 map 中添加新值,主要是 mapassign 函数,基本逻辑与查找相似,但多了写保护和扩容的内容

4. 删除
删除主要是 mapdelete 函数,逻辑如下,删除操作的实质是将值置空,并没有减少内存
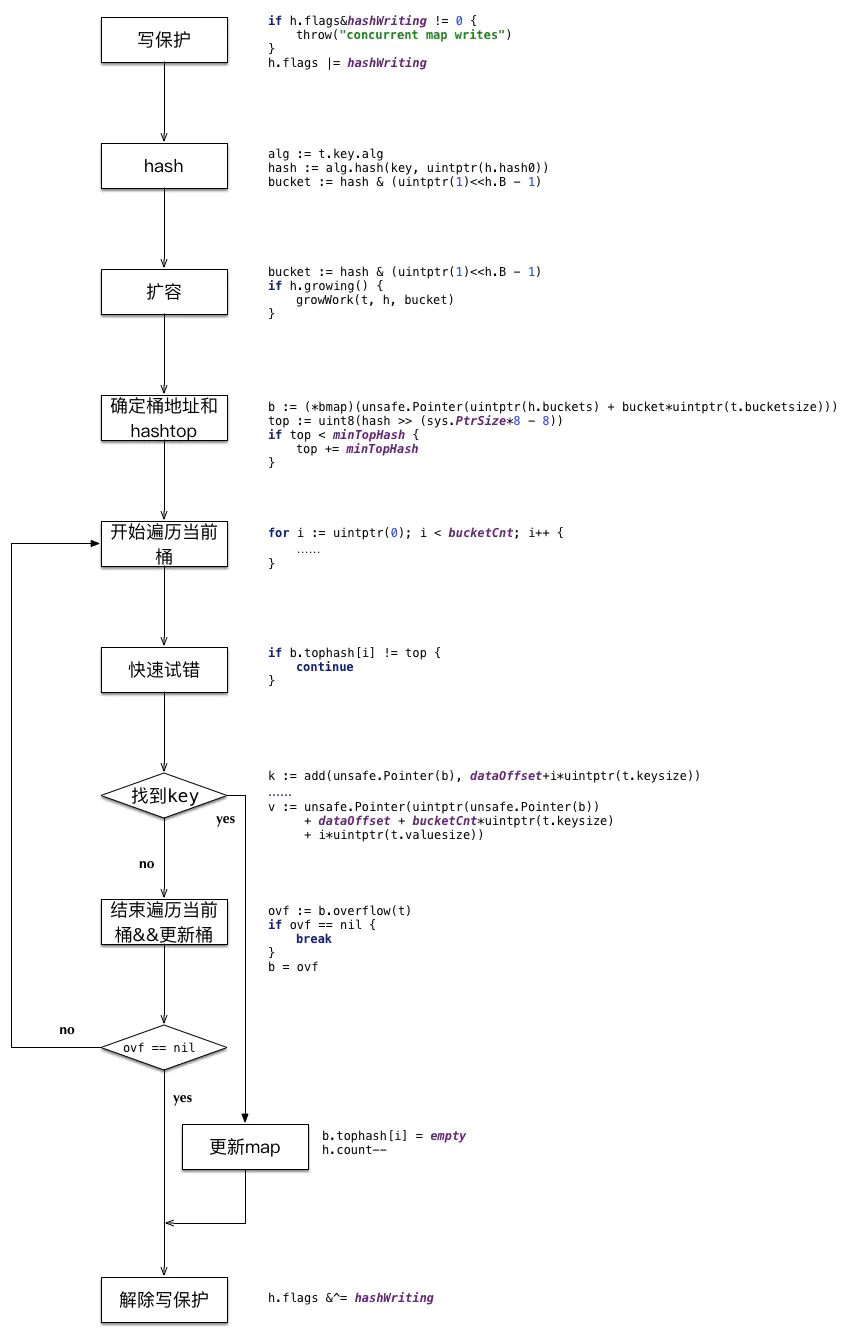
5. 遍历
Go 中 map 遍历的一个突出特征就是元素顺序的随机化,即每次遍历得到的元素的顺序不一定相同,和元素的插入顺序无关。
Go 中遍历的基本逻辑是先调用 mapiterinit 初始化 hiter 结构体,然后利用 该结构体进行遍历。
6. 扩容
首先,判断是否需要扩容的逻辑是
1
2
3
| func (h *hmap) growing() bool {
return h.oldbuckets != nil
}
|
何时h.oldbuckets不为nil呢?在分配assign逻辑中,当没有位置给key使用,而且满足测试条件(装载因子>6.5或有太多溢出通)时,会触发hashGrow逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| func hashGrow(t *maptype, h *hmap) {
//判断是否需要sameSizeGrow,否则"真"扩
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
// 将buckets复制给oldbuckets
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// 更新 hmap 结构
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// 设置溢出桶
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
|
这里需要明白,map 扩容时每次增大一倍,方法是分配一个新的 Bucket 数组,然后将就数组复制过去。
参考
[1] 简书,Love语鬼,Golang map的底层实现
 支付宝
支付宝 微信
微信