Golang深入学习7-调度器与垃圾回收
调度器和垃圾回收都属于 runtime 的一部分,本文我们介绍 Go 中 runtime 的含义,然后再来分析 Go 的调度器和垃圾回收策略。
1. runtime
runtime,直译为运行时,之前只听说过这个概念,但要解释 runtime 究竟是什么,还是说不出口。我从 Go 官方文档的问答里找到了下面这段话,可以作为一个很好的开始。
Go does have an extensive library, called the runtime, that is part of every Go program. The runtime library implements garbage collection, concurrency, stack management, and other critical features of the Go language. Although it is more central to the language, Go’s runtime is analogous to
libc, the C library.It is important to understand, however, that Go’s runtime does not include a virtual machine, such as is provided by the Java runtime. Go programs are compiled ahead of time to native machine code (or JavaScript or WebAssembly, for some variant implementations). Thus, although the term is often used to describe the virtual environment in which a program runs, in Go the word “runtime” is just the name given to the library providing critical language services.
Go 的运行时是每个 Go 程序的一部分,负责实施垃圾回收、并发、栈管理以及其它 Go 的一些核心特性。但是,尽管这些都是一个语言的核心,runtime 在 Go 中实际上是一个库(标准库的一个)。理解这一点很重要,因为在其它一些语言中,比如 Java,runtime 实际上包含一个虚拟机的概念,是程序运行的环境,但在 Go 中 runtime 就仅仅是一个包含一些关键特性的库。
这里已经说的比较清楚了,接下来我们来看 runtime 库包含哪些东西,实际上,runtime 库下面还有几个子库
- runtime/cgo:用来支持 C 语言函数的调用
- runtime/debug:进行问题排查
- runtime/msan
- runtime/pprof:进行性能分析
- runtime/race:实现了数据静态检测逻辑
- runtime/trace:执行跟踪器,捕获各种执行时的事件,比如 goroutine 的创建/阻塞/解除阻塞、系统调用的进入/退出/阻塞、垃圾回收相关的事件、堆大小的改变、处理器的启动和停止等,并将它们写入 io.writer 中
需要知道的是,调度器、垃圾回收、各种数据类型的定义和操作(比如切片、接口等)都位于 runtime 库,而不是这几个子库,在电脑中的位置为 $GOROOT/src/runtime
Go 的可执行文件一般比相应的源码文件大很多,这是因为 runtime 潜入了每一个可执行文件中,因此,Go 运行不依赖于其它任何文件。
2. 调度器
这部分关于调度器的介绍,主要翻译自 The Go scheduler 这篇文章,写的非常容易理解。
在操作系统中,调度主要是对 CPU 时间片的分配策略,为了充分利用 CPU,将时间划分为一系列的时间片,然后遵循某种最优的策略(总执行时间最短或其它)将进程分配到某个时间片执行的过程。Go 中的调度做的也是类似的事,也就是如何分配 Goroutine 的执行,做这件事的工具就是调度器,而且我们也可以看出,调度器和 Go 的并发是息息相关的。
2.1 设计理念
我们首先来理解为什么 Go 需要一个自己的调度器,而不是使用操作系统的调度器。首先,在操作系统中,线程的上下文切换也需要一定的资源,其中很多开销对 Go 的运行来说是不必要的,而且线程数量越多,这部分开销越大。另外一个重要的原因是交给操作系统调度无法基于 Go 当前的情况做出最优的调度决策,比如 Go 进行垃圾回收的时候,需要暂停正在运行的 Goroutine 和线程,并使内存保持在一个一致的状态,如果交给操作系统的调度器,就失去了对一致性状态的把握,并且需要等待所有相关线程停止工作,正在运行的线程越多,达到这个目的越难。如果 Go 使用自己的调度器,就知道什么时候内存状态是一致的(只针对 Go 程序分配的内存),它会在这些已知的内存一致性的时刻开始垃圾回收,并且此时只需要等待当前正在 CPU 核上执行的那个线程,而不是等待所有的线程。
有三种常见的线程模型,第一种是 N:1,也就是多个用户空间线程运行在一个 OS 线程上,其优点是上下文切换快速,缺点是不能充分利用多核系统的优点;第二种是 1:1,也就是一个用户空间线程对应一个 OS 线程,其优点是充分利用了系统的多个核,缺点是上下文切换的开销有点大。
Go 采用的是一种折衷的办法,即 M:N,也就是将任意数量的 Goroutine 对应到任意数量的 OS 线程,OS 线程的数量通常取决于 CPU 核的数目,这种方式保持了较低的上下文切换开销,并且充分利用了多核系统的优点,它主要的缺点是增加了调度器的复杂性。
Go 的调度器定义在 runtime 包中,具体的文件是 src/runtime/proc.go,最主要的概念有三个:P,M,G。其定义如下
| |
用图形描述更直观一点
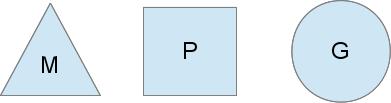
M 是 OS 线程,由操作系统管理,是实际的执行者,M 是 Machine 的首字母大写。
G 是 Goroutine,它包括堆栈,指令指针和其他对调度 Goroutine 重要的信息。
P 是调度的上下文,可以看作 Go 自己的调度器,负责将 Goroutine 调度到具体的 OS 线程上执行,他是实现 M:N 模型的关键,P 是 Processor 的首字母大写。
2.2 调度策略
我们基于上面的三个概念来描述 Go 的调度策略。
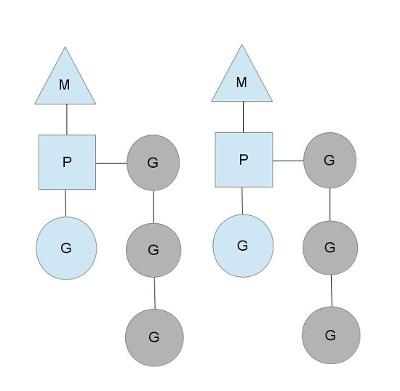
上图中有两个 M,每个线程 M 都持有一个调度器 P,并且运行着一个 G。调度器的数目可以通过设置 GOMAXPROCS 环境变量或者调用 runtime.GOMAXPROCS 函数来设定,通常在设定好后,程序运行期间该值不会改变。事实上,该值的设定是充分利用多核的关键,比如,如果有一个 4 核的计算机,我们通常将 GOMAXPROCS 设定为 4,这样操作系统中会同时有 4 个线程运行 Goroutine。
灰色的 G 意味着 Goroutine 没有在运行,而是处于等待被调度的状态,这里使用了一个队列来存放它们,称为运行队列(runqueue)。每当使用 go 关键字启动一个 Goroutine 时,它就被加入运行队列的尾部,当 P 到达某个调度的时刻,就从运行队列首部取出一个 Goroutine ,设置好堆栈和指令指针,然后分配给关联的 M 运行。为了减少争用,每个 P 都有自己的运行队列。
注:早期的时候所有 P 公用一个运行队列,但这种情况下调度时需要加解锁,线程经常被阻塞。
运行队列不空,P 有用来调度的 Goroutine,那么就不会发生意外,调度会处于一个稳定的状态。但实际环境下是会产生意外的,我们介绍如下:
线程出于某些原因需要阻塞。这时候 P 无法再将 Goroutine 交给自己的 M 运行,然后就会将 Goroutine 移交给其它的 M 运行。
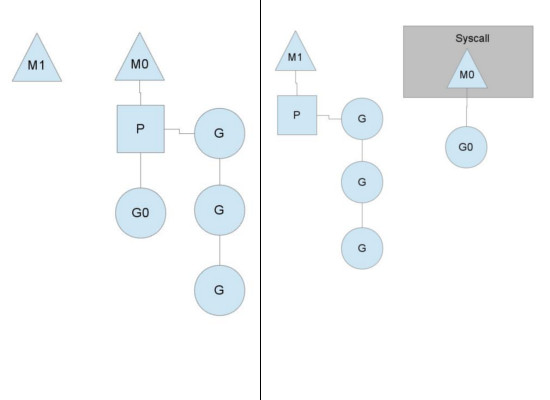
如上图,我们可以看到 M0 由于系统调用(syscall)发生了阻塞,与之相关的 P (实际上是下文)就被移交给了 M1(这里我们可以更好的理解为什么 P 的本质是上下文,只是可以看作调度器)。调度程序会确保有足够的 M 来运行 P,上面的 M1 可能仅为了处理移交的 P 和对应的 Goroutine创建,也可能来自线程池。M0 将保留正在执行的 Goroutine,因为实质上它仍然在执行,只是在 OS 中被阻塞。
当 syscall 返回时,M0 必须尝试获取一个 P 用来执行未执行完的 G0,一般情况是从其它线程窃取一个 P,如果无法窃取到,就会把 G0 放到全局的运行队列中,然后把自己放到线程池进入睡眠状态。
全局的运行队列是 P 从自己的运行队列无法获取到 G 时读取的地方,P 会定期检测全局运行队列,防止全局运行队列中的 Goroutine 始终得不到执行。
这种处理过程说明了为什么即使 GOMAXPROCS=1,Go 程序运行也会涉及到多个线程,G0 会停留在syscall 线程上。
运行队列中的 Goroutine 被用尽了。如果每个 P 的运行队列上 Goroutine 的数量不平衡,就可能发生这种情况
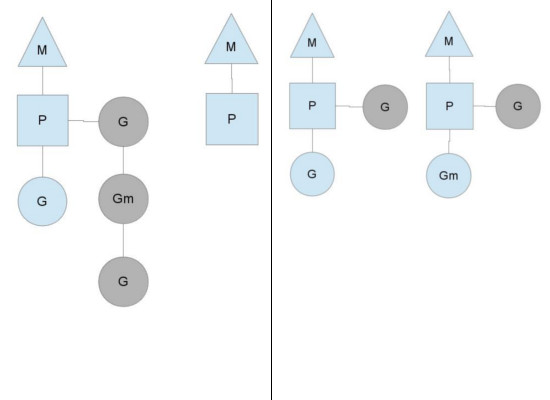
前面已经提到,P 本身的运行队列空了的时候,会从全局运行队列获取 Goroutine,那么,如果全局运行队列也为空呢。P 就会从其它 P 那里窃取 Goroutine,一般情况下会窃取大约一半的运行队列,这样可以保证两个 P 一直有 Goroutine 可调用,也就是保持平衡,从而保证所有的线程不处于空闲状态。上图中空闲 P 从其它 P 窃取了两个 Goroutine,一个直接开始执行,剩下的放入运行队列,此时两个 P 的运行队列大小相同。
所以,在操作系统层面,Go 采用的是抢占式调度,如果 M 陷入了阻塞,那么会导致当前在它上面的 Goroutine 长时间占用 M,这时候就会发生抢占, P 会寻找其它的 M,然后把 G 交给新的 M 调度。但是在语言层面,后来的 Goroutine 永远假如运行队列的末尾,不会抢占 P。
非抢占式调度是进程/线程交给 CPU 后,会一直执行完毕,不会被中断;
抢占式调度是 CPU 正在执行的进程/线程会被具有更高优先级的进程/线程抢占掉(可以防止单一进程长时间独占 CPU)。
其它参考:说说Golang的runtime
3. 垃圾回收
垃圾回收(Garbage Collection,GC),是一种存储管理机制。我们编写的程序中,变量、函数参数等在内存通常存放在两个不同的区域:栈和堆。栈的分配由操作系统管理,而堆的分配由程序员管理,在 C 和一些语言中,程序员使用 malloc 申请空间后,最后还需要自己使用 free 释放空间,编译器不会辅助完成这个过程,如果忘记释放,就可能造成不可预知的后果(内存泄漏等)。而在 Go 和另一些编程语言中,主动提供了一种机制,它会在后台持续的运行,监控各个变量和参数的状态,识别那些不再使用的对象并释放掉它们的内存空间,这种机制(或者说这个后台进程)叫做垃圾回收。
3.1 常见的GC算法
有很多用于垃圾回收的算法。
第一个叫做引用计数,方法是为每个对象添加一个引用计数器,每当有引用指向该对象,计数器+1,释放时计数器-1,当 GC 检测到计数器为 0 时,说明该对象不再被使用,就回收为它分配的内存。其缺点是无法检测到循环引用,因为循环引用的引用计数永远不可能为 0。
第二个叫做根搜索算法,Java 和 C# 使用了这种办法。原理是通过一系列称为 GC Root 的对象作为起点,从这些节点向下搜索,所走过的路径称为引用链(Reference Chain),如果一个对象到 GC Root 没有任何引用链相连,那么就说明该对象的内存可以被回收。Java 中可以作为 GC Root 的对象包括虚拟机栈中的引用对象、类静态属性引用的对象、常量引用的对象和本地方法栈中的引用对象。
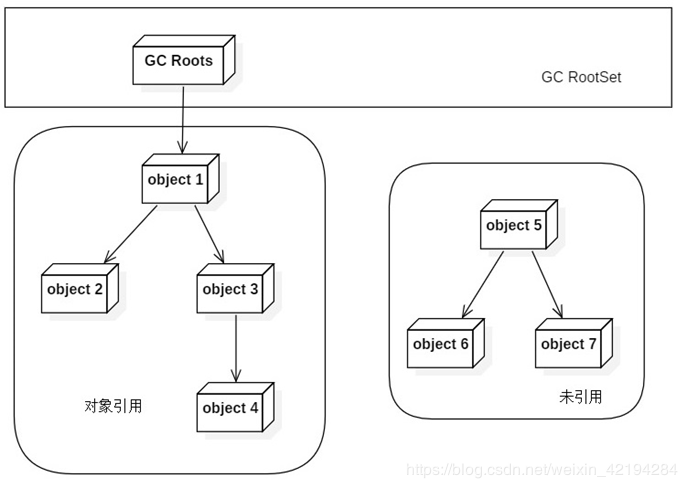
第三种叫做标记-清除算法。它将垃圾回收划分为两个阶段,在标记阶段标记所有可回收的对象,然后在回收阶段回收被标记对象占用的空间。其缺点主要有两个,第一个是标记时需要暂停整个程序的运行,第二个是会产生大量的内存碎片,如下图,碎片比较多的话后续可能没有足够的连续内存分配给需求较多的对象。
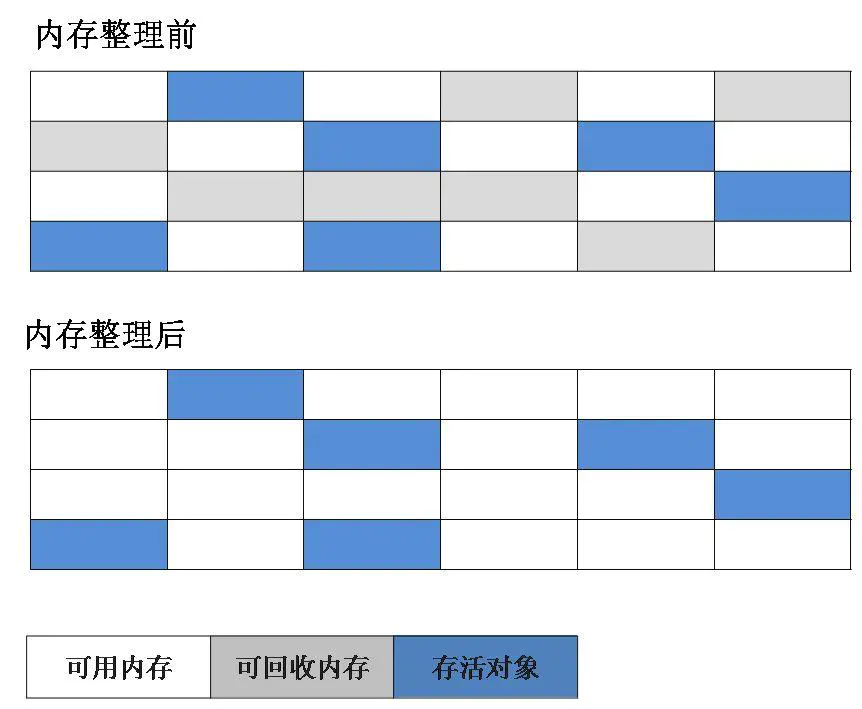
第四种是复制算法。复制算法是标记-清除算法的改进,它将内存分为两个相等的区域,每次只使用其中一个区域,进行垃圾回收时,会把当前存活的所有对象复制到另一个空间,然后堆当前空间进行回收。如下图,这种算法解决了内存碎片的问题,代价是可使用的内存为原理的一半,并且由于额外的复制操作,效率会有一定的影响。
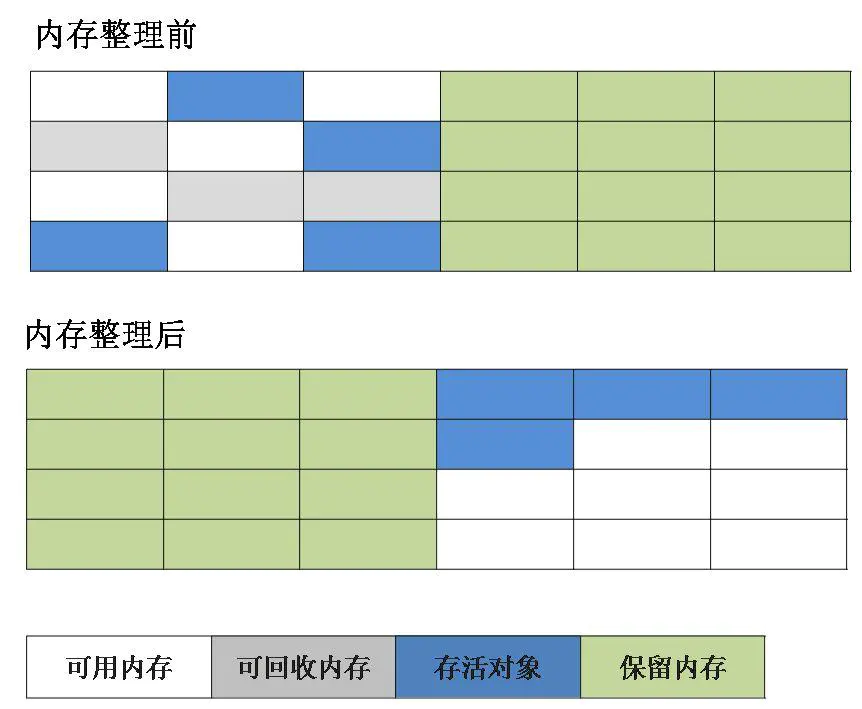
第五种是标记-压缩算法。标记-压缩算法与复制算法思路相似,都是将内存分两块,不同在于,标记完可回收的对象后,标记-压缩算法会将存活的对象压缩到内存的一端,让它们紧凑的排列在一起,然后对边界以外的空间进行回收,回收后,已用和未用的内存各自在一边。如下图,标记压缩算法解决了内存碎片问题和回收效率低的问题。

第六种是分代收集。分代收集是一种思路,研究发现,程序中大部分对象的生命周期都很短,所以根据对象生命周期的长短,使用不同的垃圾回收算法。生命周期比较长的叫做老年代,通常使用标记-压缩算法,生命周期比较短的叫做新生代,通常使用复制算法。
本节主要参考:简书,顾林海,垃圾回收算法有哪些
3.2 Go的垃圾回收
Go 的垃圾回收经历了一个比较长的演变过程,具体可以参考 The Journey of Go’s Garbage Collector 这篇文章。
目前 Go 使用的是三色标记法。三色标记法是标记-回收算法的一种改进,它将所有的对象用白色、灰色、黑色三种颜色表示,基本步骤如下
开始时将所有对象标记为白色;
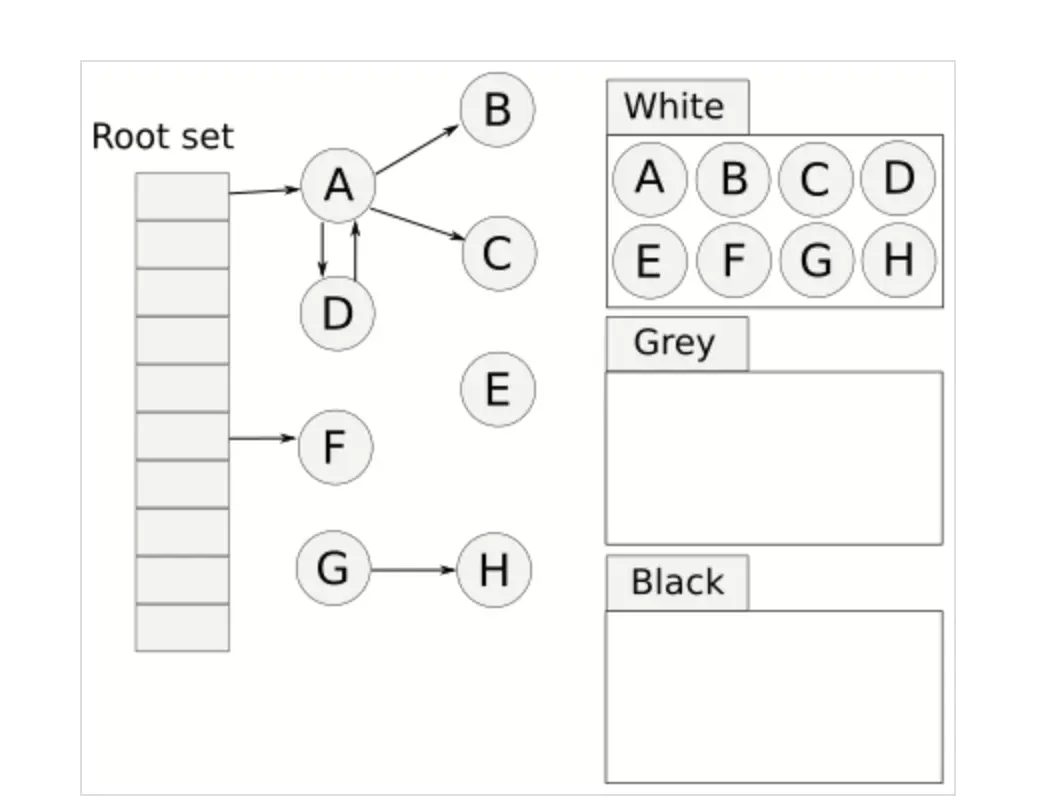
GC 从根结点开始扫描,下图中,A 和 F 是根结点,所以将它们标记为灰色(注意这一步标记为灰色的是根结点集合的所有对象)
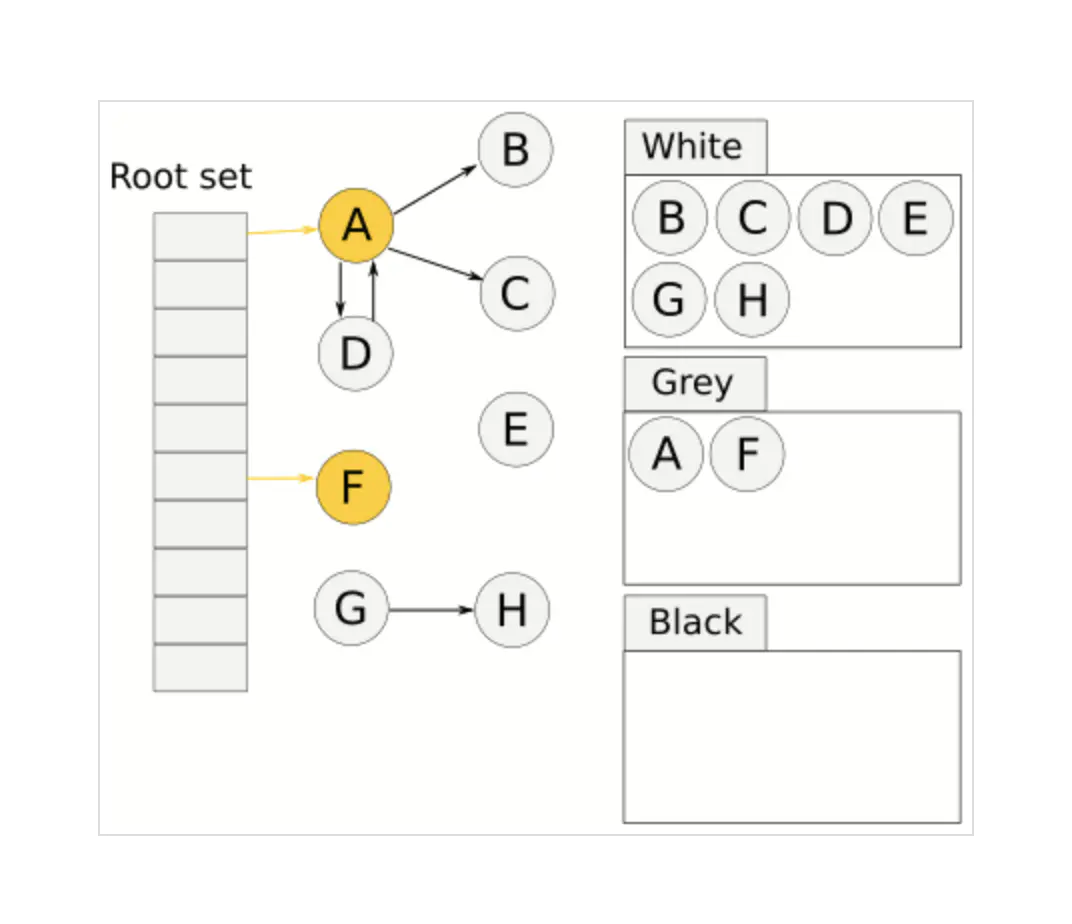
遍历灰色节点,将灰色节点所引用的节点也标记为灰色,这里 A 引用了 B、C、D,F 没有引用,然后将分析过的灰色节点标记为黑色,如下图
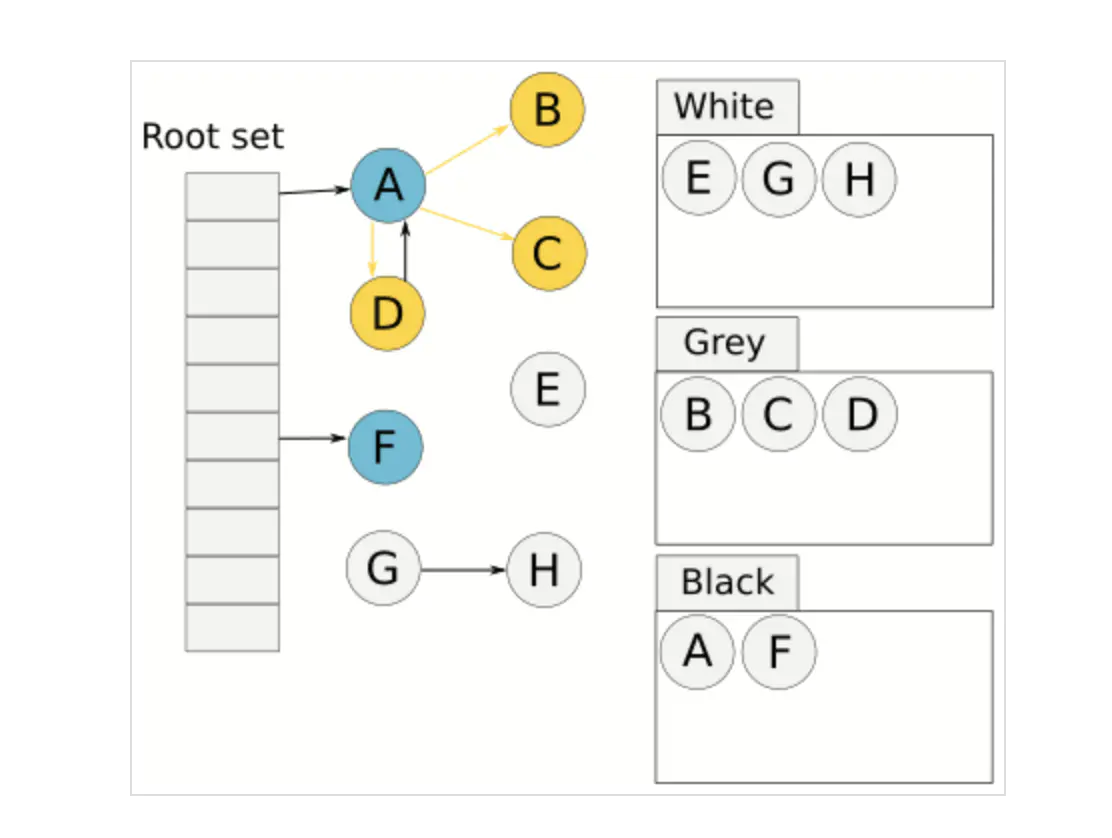
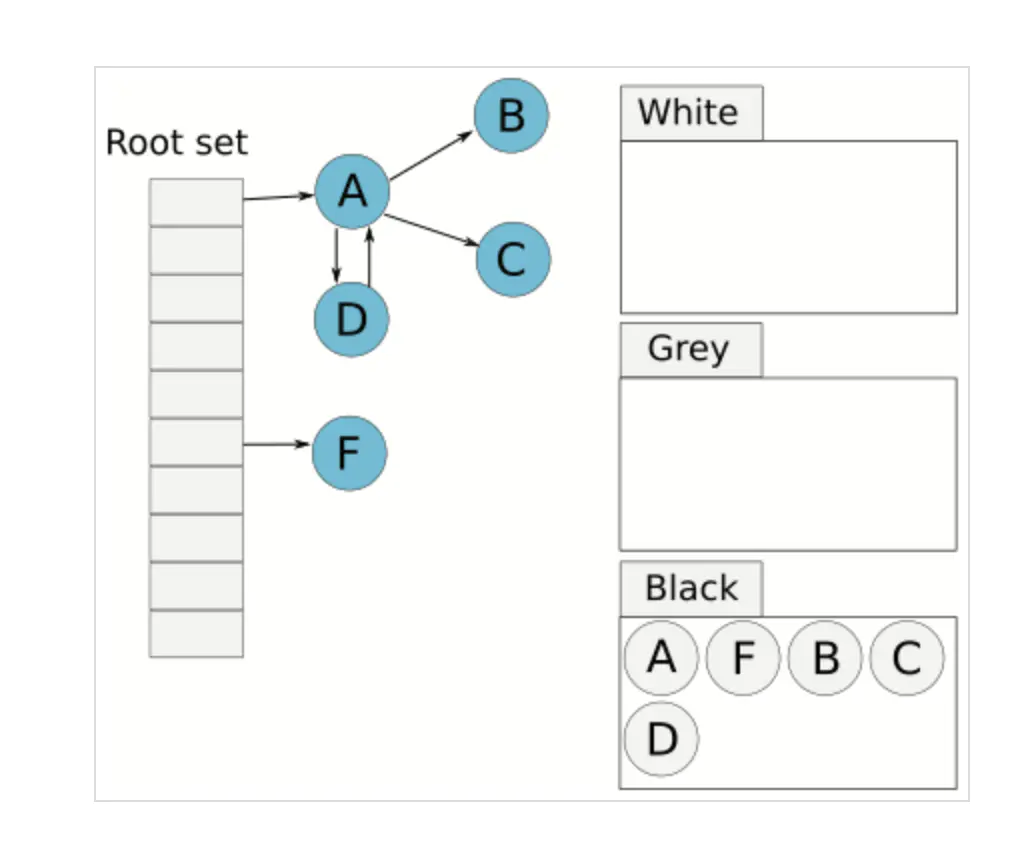
循环遍历灰色节点,直到灰色节点的个数为 0,下图中,B、C、D都没有引用的白色节点,所以这一轮都标记为了黑色

此时对白色节点对应的内存空间进行垃圾回收
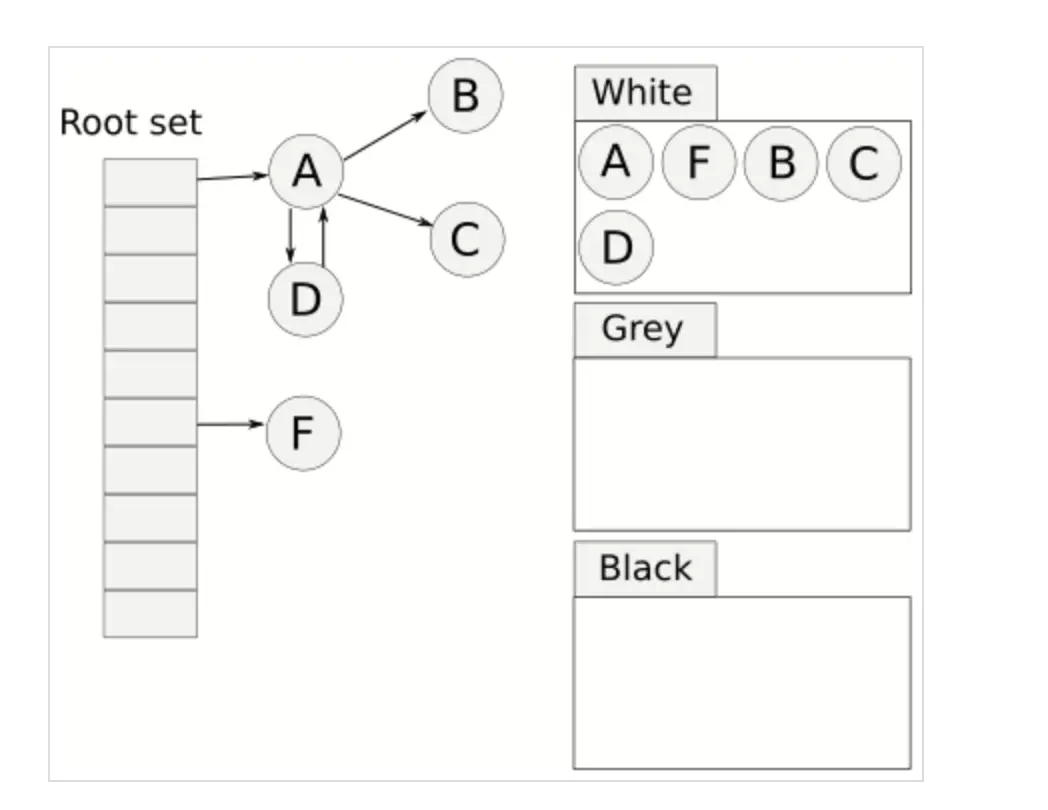
最后,GC 将黑色节点再次重置为白色,供下一次垃圾回收使用。
除了三色标记的主过程外,还需要写屏障(Write Barrier)的配合。由于三色标记是可并发执行的,运行过程中就可能出现新分配的对象,对于这些对象如何处理就需要写屏障参与。写屏障类似于写锁,主要用于保证并发的一致性。写屏障在标记开始时打开,在标记结束后关闭。(需要进一步理解)
另外一个概念是 STW(Stop the world),这是标记阶段产生的一种行为,意思是停止所有的 Goroutine。
3.3 其它
有 GC 不意味着高枕无忧,也可能发生内存泄漏,所以要养成一些良好的习惯,比如不使用的指针置为 Nil。
runtime包有两个关于垃圾回收的 API
| |
自动垃圾回收触发的条件有两个:
- 超过内存大小阈值
- 达到定时时间(默认2min触发一次)
如果想知道当前的内存状态,可以使用
| |
上面的程序会给出已分配内存的总量,单位是 Kb。进一步的测量参考 package runtime
垃圾回收参考:
[1] 简书,Go垃圾回收之三色标记算法
[2] 博客园,搞懂Go垃圾回收
[3] 知乎专栏,张三毛,Go垃圾回收系列
 支付宝
支付宝 微信
微信